

MapReduce en JavaScript: Cómo manejar grandes conjuntos de datos con eficiencia
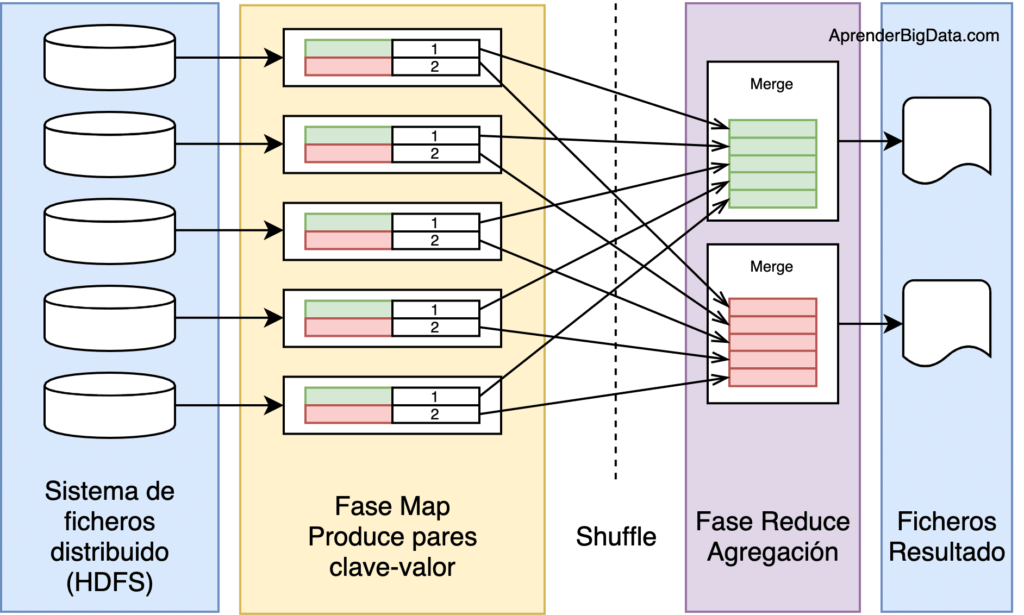
MapReduce es un modelo de programación para procesamiento distribuido y paralelo de grandes conjuntos de datos. Este modelo se divide en dos fases: la fase de map y la fase de reduce.
La fase de map aplica una función de map a cada elemento de un conjunto de datos, transformando los datos en pares clave-valor. Luego, la fase de reduce aplica una función de reduce a los pares clave-valor generados por la fase de map, produciendo un conjunto más pequeño de pares clave-valor.
JavaScript es un lenguaje de programación popular y ampliamente utilizado en aplicaciones web. En este artículo, exploraremos cómo implementar MapReduce en JavaScript para manejar grandes conjuntos de datos con eficiencia.
Implementando MapReduce en JavaScript
Para implementar MapReduce en JavaScript, utilizaremos la función map() y la función reduce() de la clase Array de JavaScript.
Supongamos que tenemos un gran conjunto de datos en forma de un Array de objetos JavaScript. Queremos aplicar una función de map a cada objeto en el Array, y luego aplicar una función de reduce a los pares clave-valor generados por la función de map.
const datos = [
{id: 1, valor: 10},
{id: 2, valor: 20},
{id: 3, valor: 30},
{id: 4, valor: 40},
{id: 5, valor: 50}
];Fase de map
En la fase de map, aplicamos una función de map a cada objeto en el Array datos. La función de map toma un objeto como entrada y devuelve un par clave-valor. En nuestro ejemplo, la función de map asignará el valor de id como clave y el valor de valor como valor.
const pares = datos.map(objeto => ({clave: objeto.id, valor: objeto.valor}));La función map() devuelve un nuevo Array de objetos que contiene los pares clave-valor generados por la función de map.
[
{clave: 1, valor: 10},
{clave: 2, valor: 20},
{clave: 3, valor: 30},
{clave: 4, valor: 40},
{clave: 5, valor: 50}
]Fase de reduce
En la fase de reduce, aplicamos una función de reduce a los pares clave-valor generados por la fase de map. La función de reduce toma dos argumentos: el valor acumulado y el valor actual. En nuestro ejemplo, la función de reduce sumará los valores de valor para cada clave.
const resultado = pares.reduce((acumulado, actual) => {
if (!acumulado[actual.clave]) {
acumulado[actual.clave] = 0;
}
acumulado[actual.clave] += actual.valor;
return acumulado;
}, {});La función reduce() devuelve un objeto que contiene los resultados de la función de reduce aplicada a los pares clave-valor generados por la función de map.
{
1: 10,
2: 20,
3: 30,
4: 40,
5: 50
}
Manejando grandes conjuntos de datos
Cuando se manejan grandes conjuntos de datos, MapReduce en JavaScript puede mejorar significativamente el rendimiento del procesamiento de datos. Sin embargo, es importante tener en cuenta algunos aspectos clave para lograr la eficiencia en el procesamiento de grandes conjuntos de datos.
División de datos
En la fase de map, se debe dividir el conjunto de datos en partes más pequeñas y procesar cada parte en paralelo en varios hilos de ejecución o nodos. Esto permitirá que el procesamiento se realice más rápido y reducirá la carga de trabajo en cada hilo de ejecución o nodo.
JavaScript no tiene soporte nativo para la ejecución en paralelo de hilos de procesamiento, pero existen algunas bibliotecas externas que permiten la ejecución en paralelo de funciones. Una de ellas es la biblioteca webworker-threads.
const Worker = require('webworker-threads').Worker;
const datos = [
{id: 1, valor: 10},
{id: 2, valor: 20},
{id: 3, valor: 30},
{id: 4, valor: 40},
{id: 5, valor: 50}
];
const num_hilos = 2; // número de hilos de procesamiento
const dividir_datos = (datos, num_hilos) => {
const datos_por_hilo = Math.ceil(datos.length / num_hilos);
const datos_divididos = [];
for (let i = 0; i < num_hilos; i++) {
datos_divididos.push(datos.slice(i * datos_por_hilo, (i + 1) * datos_por_hilo));
}
return datos_divididos;
};
const procesar_datos_en_paralelo = (datos, num_hilos, funcion_map, funcion_reduce, callback) => {
const datos_divididos = dividir_datos(datos, num_hilos);
let resultados_parciales = [];
let hilos_procesamiento = [];
for (let i = 0; i < num_hilos; i++) {
const hilo_procesamiento = new Worker(function () {
const pares = datos_divididos[this.threadId].map(funcion_map);
const resultado_parcial = pares.reduce(funcion_reduce);
postMessage(resultado_parcial);
});
hilo_procesamiento.onmessage = (event) => {
resultados_parciales[this.threadId] = event.data;
if (resultados_parciales.length === num_hilos) {
const resultado_final = resultados_parciales.reduce(funcion_reduce);
callback(resultado_final);
}
};
hilos_procesamiento.push(hilo_procesamiento);
}
};
const funcion_map = (objeto) => {
return {clave: objeto.id, valor: objeto.valor};
};
const funcion_reduce = (acumulado, actual) => {
if (!acumulado[actual.clave]) {
acumulado[actual.clave] = 0;
}
acumulado[actual.clave] += actual.valor;
return acumulado;
};
procesar_datos_en_paralelo(datos, num_hilos, funcion_map, funcion_reduce, (resultado_final) => {
console.log(resultado_final);
});
En este ejemplo, hemos utilizado la biblioteca webworker-threads para procesar los datos en dos hilos de ejecución en paralelo. Hemos dividido los datos en dos partes iguales y hemos procesado cada parte en un hilo de ejecución separado.
Reducción de resultados
En la fase de reduce, se deben combinar los resultados parciales generados por los hilos de ejecución o nodos en un único resultado final. Esto se puede lograr utilizando la función reduce de JavaScript.
const datos = [
{id: 1, valor: 10},
{id: 2, valor: 20},
{id: 3, valor: 30},
{id: 4, valor: 40},
{id: 5, valor: 50}
];
const funcion_map = (objeto) => {
return {clave: objeto.id, valor: objeto.valor};
};
const funcion_reduce = (acumulado, actual) => {
if (!acumulado[actual.clave]) {
acumulado[actual.clave] = 0;
}
acumulado[actual.clave] += actual.valor;
return acumulado;
};
const resultado_parcial_1 = datos.slice(0, 2).map(funcion_map).reduce(funcion_reduce);
const resultado_parcial_2 = datos.slice(2, 4).map(funcion_map).reduce(funcion_reduce);
const resultado_parcial_3 = datos.slice(4).map(funcion_map).reduce(funcion_reduce);
const resultado_final = [resultado_parcial_1, resultado_parcial_2, resultado_parcial_3].reduce(funcion_reduce);
console.log(resultado_final);
En este ejemplo, hemos utilizado la función reduce de JavaScript para combinar los resultados parciales generados por los hilos de ejecución en un único resultado final. Hemos dividido los datos en tres partes y hemos procesado cada parte en un hilo de ejecución separado. Luego, hemos combinado los tres resultados parciales utilizando la función reduce.
Limitaciones de MapReduce en JavaScript
A pesar de que MapReduce en JavaScript puede mejorar significativamente el rendimiento del procesamiento de grandes conjuntos de datos, existen algunas limitaciones que se deben tener en cuenta.
En primer lugar, JavaScript no tiene soporte nativo para la ejecución en paralelo de hilos de procesamiento, lo que puede limitar el rendimiento del procesamiento en función del número de hilos de procesamiento que se utilicen.
En segundo lugar, JavaScript no es un lenguaje diseñado para el procesamiento de grandes conjuntos de datos, por lo que es posible que se requieran algunas técnicas adicionales para mejorar el rendimiento del procesamiento.
Por último, MapReduce en JavaScript puede no ser adecuado para todas las aplicaciones de procesamiento de datos. Es importante evaluar cuidadosamente las necesidades de procesamiento de datos de una aplicación antes de decidir utilizar MapReduce en JavaScript.
Conclusión
MapReduce es un paradigma de procesamiento de datos distribuido que puede mejorar significativamente el rendimiento del procesamiento de grandes conjuntos de datos. En JavaScript, se puede implementar MapReduce utilizando las funciones map y reduce de JavaScript, junto con algunas técnicas adicionales para el procesamiento en paralelo de hilos de ejecución.
Sin embargo, es importante tener en cuenta que JavaScript no es un lenguaje diseñado específicamente para el procesamiento de grandes conjuntos de datos, por lo que es posible que se requieran algunas técnicas adicionales para mejorar el rendimiento del procesamiento. Además, JavaScript no tiene soporte nativo para la ejecución en paralelo de hilos de procesamiento, lo que puede limitar el rendimiento del procesamiento en función del número de hilos de procesamiento que se utilicen.
A pesar de estas limitaciones, MapReduce en JavaScript sigue siendo una herramienta valiosa para el procesamiento de grandes conjuntos de datos en ciertas aplicaciones. Es importante evaluar cuidadosamente las necesidades de procesamiento de datos de una aplicación antes de decidir utilizar MapReduce en JavaScript y, en algunos casos, considerar otras alternativas de procesamiento de datos.
En resumen, MapReduce en JavaScript es una técnica eficaz para procesar grandes conjuntos de datos. Aunque tiene algunas limitaciones, estas se pueden superar utilizando técnicas adicionales. Si bien no es adecuado para todas las aplicaciones de procesamiento de datos, es una herramienta valiosa que puede mejorar significativamente el rendimiento del procesamiento de grandes conjuntos de datos en ciertos casos.

